
-
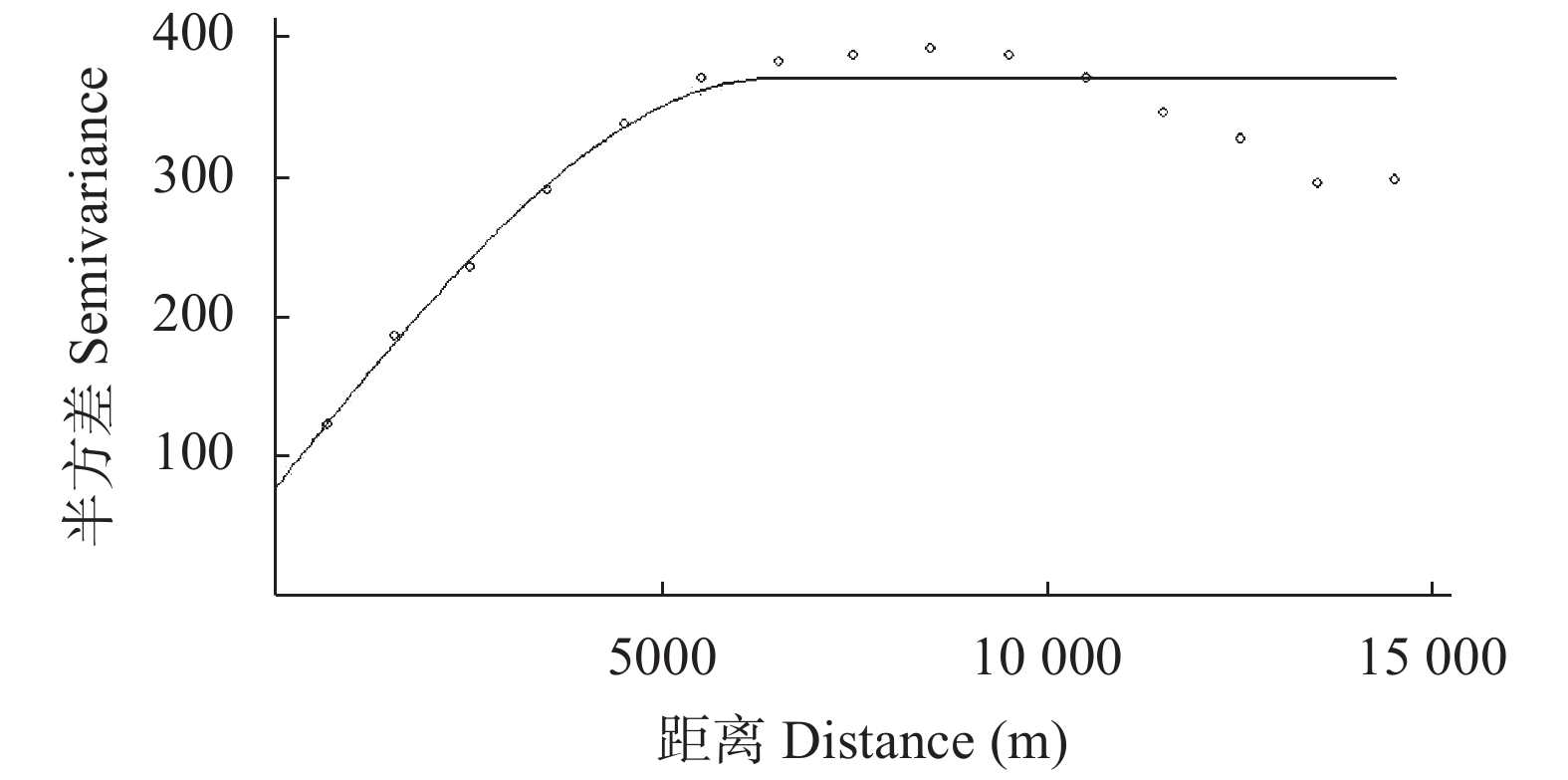
摘要: 土壤环境变量具有较强空间异质性, 为空间插值精度的提升带来了困难, 仅基于空间相关性和空间异质性的空间插值方法难以获得较高的插值精度。机器学习方法能够融合多维辅助变量的信息, 提高土壤属性的插值精度, 但是不能有效融合空间位置关系信息进一步改善插值精度。本文基于随机森林空间预测框架, 将空间半变异函数与随机森林算法融合, 提出了融合半变异函数的空间随机森林插值方法。应用所提出的方法对湖南省湘潭县土壤重金属数据进行空间插值, 并与随机森林方法、基于距离的随机森林空间预测方法、普通克里金方法和回归克里金方法进行对比, 检验了所提出方法的插值精度。结果表明, 融合半变异函数的空间随机森林插值方法相较于传统克里金方法精度提升10%以上, 相较于新型机器学习空间插值方法精度提升5%以上, 同时基于半变异函数的空间随机森林插值方法的插值制图结果具有更加合理的空间分布和丰富的细节信息。因此, 融合半变异函数的空间随机森林插值方法能够有效结合辅助变量信息与空间位置关系信息, 有效提高土壤环境变量插值精度。Abstract: The strong spatial heterogeneity of soil environmental variables causes difficulties in improving spatial interpolation accuracy. It is difficult to obtain a high interpolation accuracy by leveraging spatial correlation and spatial heterogeneity. Machine learning methods can fuse the information of multi-dimensional auxiliary variables to improve the interpolation accuracy of soil attributes, but they cannot effectively utilize the spatial position relationship information to further improve the interpolation accuracy. Based on the random forest spatial prediction framework, this study combined the spatial semi-variogram with the random forest algorithm and proposed a spatial random forest interpolation method with a semi-variogram. Taking soil heavy metal data from the Xiangtan County of Hunan Province as an example, the proposed method was used to implement spatial interpolation of soil Cr. The interpolation accuracy was compared with the random forest method, distance-based random forest spatial prediction method, ordinary Kriging method, and regression Kriging method. The results showed that the accuracy was improved by more than 10% compared with the traditional Kriging method. Compared with the new machine learning spatial interpolation method, the accuracy was improved by more than 5%. Furthermore, the mapping of the proposed results had a more reasonable spatial distribution and detailed information. Thus, we concluded that the proposed method could effectively combine auxiliary variable information and spatial location information and improve the interpolation accuracy of soil environmental variables.
-
Keywords:
- Spatial interpolation /
- Random Forest /
- Semi-variogram /
- Machine Learning /
- Regression Kriging
-
精准扶贫背景下, 山区所占贫困人口巨大, 而且出现空心村、土地利用率低、卫生较差、饮水困难、产业单一等一系列问题[1-3]。《中国农村贫困监测报告》数据显示, 2008年山区贫困人口占全国农村贫困人口比重为80.2%[4], 2011—2016年连片特困地区中八成以上的贫困人口聚集在山区, 太行山也是全国农村贫困连片地区之一。了解山区贫困状况, 寻求山区贫困根源, 对指导山区脱贫意义重大[5]。然而传统的收入贫困方法衡量个体或家庭贫困不符合现实, 需要从多角度来评价贫困, 然后进行有针对性的解决, 才能做到真正的精准扶贫。多维贫困理论指从多维角度理解贫困, 其主要创始者Sen[6]以“能力方法”作为理论基础, 强调“真实自由的扩展” “多维度” “个体能力差异” “机会”等促进生活质量提高的关键要素。联合国开发计划署(The United Nations Development Programme, UNDP)在《1997年人类发展报告》中也提出贫困包括发展机会、权利和健康等多方面内容。可见, 多维贫困理论更科学、合理。
选择科学实用的测度方法是多维贫困研究的重要基础。早期的贫困测算方法为边际计算方法, 此法是用一维的方法测算被研究者的被剥夺程度, 缺点是无法识别贫困人口[7]。所以有学者在此基础上提出基于微观数据的联合分布计算方法[8-10], 但也存在缺乏可对比的综合性指标的缺点。也有学者使用Watts[11]、HPI(人类发展指数, human poverty index)[12]等测算多维贫困, Watts法能综合反映贫困人口之间维度的分布状况, 但因计算过程使用对数并且数值较小, 计算结果往往存在偏差[13]; 而HPI指数综合一个地区所有人(含非贫困人口)的贫困情况, 主要反映国家层面的宏观信息, 并不适用于特定区域。相较而言, Alkire等[14]构建的多维贫困测量体系(A-F法)可以精确识别贫困人口, 而且应用灵活, 计算过程简便、清晰, 指标选取广泛并且科学, 可反映个体被剥夺程度, 可进行数据的分解, 在世界范围内被广泛使用。因此本文选用A-F法作为多维测度模型。
多维贫困测度实证研究主要集中于2个空间尺度, 一是国家尺度, 二是区域尺度。国家尺度多维贫困实证研究的数据源多是CHNS(China Health and Nutrition Survey, 中国健康与营养调查)数据, 如王小林等[15]基于CHNS数据测算了2006年中国城市和农村的多维贫困状况; 邹薇等[16-17]从“能力”方法角度出发, 利用CHNS数据分析了我国现阶段的能力贫困状况。区域尺度实证研究多是采用实地调查的大样本农户微观数据, 如刘伟等[18]通过分析调研数据测度了陕西安康西部山区的贫困状况, 马明义等[19]采用A-F多维贫困测度模型对陕西省太白县农户家庭进行多维贫困测度与分解。可以看出, 区域实证研究的热点区为陕西秦巴山区。同样作为连片贫困地区, 太行山区的研究热度并不高。王金营等[20]采用层次分析法建立指标体系, 从家庭特征、收支状况、经营活动和服务获得、家庭住房情况4个维度综合评价了燕山-太行山-黑龙港地区农户家庭贫困-富裕程度, 探讨了此地区的贫困-富裕标准及贫困-富裕状况, 但缺乏对多维贫困的识别, 尚不能探明太行山区贫困的深层次问题及原因。鉴于此, 本研究将视线聚焦太行山区典型乡镇, 以农户调查数据为样本, 利用A-F多维贫困测度模型, 从贫困广度与深度2方面对多维贫困进行综合测度, 并进行维度分解, 以探讨太行山区乡镇尺度的多维贫困状况与致贫机理, 以期为太行山区的精准扶贫、根源扶贫提供政策建议。
1. 研究区概况与研究方法
1.1 研究区概况
河北省平山县位于太行山中段, 是省会石家庄的饮用水源地与京津地区的备用水源地, 生态地位突出[21], 但平山县同时也是国家级贫困县。从图 1可以看出, 北冶乡的人均产值(即总产值与总人口比值)在平山县23个乡镇中居21位, 发展比较落后, 而其总面积(2016年年末平山县各乡镇面积)约占平山县总面积的8.2%, 居第2位, 地广人稀, 是较为典型的山区贫困乡。北冶乡位于深山区, 共辖42个自然村, 39个行政村, 下辖行政村有90%为国家级贫困村。2016年, 全乡贫困户约1 200户, 涵盖人口3 000以上, 扶贫任务艰巨[23]。本文依据山区乡镇特点, 立足海拔、坡度与区位3个因素, 选取北冶乡6个典型村镇作为调查区(表 1)。调查采用参与式评估(PRA)和问卷调研的方式展开, 调查主要包括收入、资本、生活水平3方面内容(表 2)以及被调查农户的基本信息。调查方式为提问式调查, 6村共发放问卷数172份, 占6村总户数的31.56%, 占北冶乡总户数的2.92%, 全部收回, 有效率为100%。
![]() 表 1 平山县北冶乡被调查村镇基本信息表Table 1. Basic information of the investigated villages in Beiye Town of Pingshan County
表 1 平山县北冶乡被调查村镇基本信息表Table 1. Basic information of the investigated villages in Beiye Town of Pingshan County村
Village问卷数
Number of questionnaires乡村户数
Number of rural households乡村人口
Rural population海拔
Altitude (m)经纬度
Latitude and longitude区位特征
Location feature下古道Xiagudao 19 42 171 300~400 113°48'20”E
38°16'2.5”N坡度平缓Smooth slope 燕尾庄Yanweizhuang 35 65 218 600~700 113°43'40”E
38°15'12”N风景区内In the scenic area 恶石Eshi 16 98 269 600 113°46'26”E
38°10'17”N坡度陡峭Steep slope 沕沕水Huhushui 33 99 337 500 113°45'27”E
38°12'22”N风景区内, 毗邻乡道
In the scenic area, adjacent to the township大桥Daqiao 28 117 457 400~500 113°42'49”E
38°16'59”N毗邻国道
Adjacent to the national road土岭Tuling 41 124 506 400~500 113°49'56”E
38°14'19”N毗邻乡道
Adjacent to the township总和Sum 172 545 表 2 平山县北冶乡山区农村多维贫困评价指标体系Table 2. Rural multi-dimensional poverty evaluation index system of Beiye Town of Pingshan County维度
Dimension指标
Index被剥夺临界值(zj)
Deprived threshold权重(wj)
Weight备注Remarks 收入(1/3)
Income年人均纯收入
Annual net income per capita家庭年人均纯收入低于全国农村贫困标准, 赋值为1
The assigned value is 1 if the annual net income per capita of family is lower than the national rural poverty standard.1/3 2015年国家农村贫困标准为2 855元
The national rural poverty standard in 2015 was 2 855 ¥资本(1/3)
Capital人均耕地面积
Arable land area per capita家庭人均耕地面积小于贫困标准值, 赋值为1
The assigned value is 1 if the cultivated area per capita of family is less than the standard value of poverty.1/9 贫困标准值[3]=平山县人均耕地面积×60%=0.106 hm2×60%= 0.064 hm2
Standard value of poverty = cultivated area per capita × 60% = 0.064 hm2生活水平(1/3)
Standard of living教育
Education家庭成员(15~39岁)存在最高学历为小学及以下或幼童(≤15岁)已辍学, 赋值为1
The assigned value is 1 if the highest education of family members (15 to 39 years old) is primary school and below or young children (≤15 years old) drop out of school.1/9 技能培训
Skill training家庭成员均未接受农业、就业技能等培训, 赋值为1
The assigned value is 1 if family members have not received training in agriculture, employment skills, etc.1/9 卫生设施
Health facilities不能使用冲水厕所, 赋值为1
No flush toilet is assigned 1.1/15 资产
Assets无手机、电视、空调、冰箱、洗衣机或者汽车中的任何一项资产, 赋值为1
The assigned value is 1 if there is no mobile phone, TV, air conditioner, refrigerator, washing machine or car in the home.1/15 饮用水
Drinking water饮用水是未经处理的自来水、井水、河水或饮水困难, 赋值为1
The assigned value is 1 if lacking drinking water or drinking water is untreated tap water, well water, river water.1/15 健康
Health家中有两人及以上患有慢性病, 或者1人及以上丧失劳动力的赋值1
The assigned value is 1 if two or more family number have chronic diseases, or one or more lose labor.1/15 燃料
Fuel未能使用电、液化气、天然气、沼气作为生活资料, 赋值为1
The assigned value is 1 if failure to use electricity, liquefied gas, natural gas, and biogas as living materials.1/15 指标赋值为1表示在此指标上被剥夺, 即在此指标上贫困。The index is assigned 1 meaning that the family is poor regarding the index. 1.2 研究方法
借鉴Alkire和Foster的A-F法[7], 对北冶乡进行多维贫困测量。该方法是目前各种多维贫困测度中应用最为广泛、最为成熟的方法[15, 24-29]。
1.2.1 多维贫困评价指标体系和权重
根据多维贫困指数(MPI)维度和指标的方法原理, 结合山区农村特点, 选取3个维度9个指标[30]构建平山县北冶乡多维贫困评价指标体系。采用牛津贫困与人类发展中心(Oxford Poverty and Human Development Initiative, OPHI)提出的维度等权重法确定各指标的权重。3个维度权重均为1/3, 维度下各指标等权赋值, 指标权重详见表 2。
1.2.2 贫困识别
1) 单一家庭的单一维度贫困识别
$${g_{ij}} = \left\{ \begin{gathered} 1, \;{x_{ij}} < {z_j} \\ 0, \;{x_{ij}} \geqslant {z_j} \\ \end{gathered} \right\}$$ (1) 式中:${g_{ij}}$赋值为1时, 表示i家庭在j指标上被剥夺, 即贫困; 赋值为0时, 表示i家庭在j指标上非贫困。其中, ${x_{ij}}$表示i家庭在j指标上的取值, ${z_j}$表示j指标的被剥夺临界值, 判定方式详见表 2。
2) 多维贫困识别
① 多维情境下单一家庭的综合贫困识别:借鉴Alkire等[7]的研究, 本文多维情境下贫困线的界定
为一个家庭各指标的加权分数之和大于等于当前维度与指标总数的比值, 即:
$$c_i^k = \left\{ \begin{gathered} 1, \;\sum\nolimits_1^9 {{g_i}_j{w_j} \geqslant \frac{k}{9}} \\ 0, \;\sum\nolimits_1^9 {{g_i}_j{w_j} < \frac{k}{9}} \\ \end{gathered} \right.$$ (2) 式中:$c_i^k$表示k维度下i家庭的贫困状态, 值为1时为被剥夺, 即贫困, 值为0时为非贫困; k表示维度(指标), 本文中k=1, 2, $ \cdots $, 9; wj指权重。
② 多维情境下单一家庭的单一指标贫困识别:
$$g_{ij}^k = \left\{ \begin{gathered} {g_i}_j, \;c_i^k = 1 \\ 0, \;c_i^k = 0 \\ \end{gathered} \right.$$ (3) 式中:$g_{ij}^k$表示k维度下i家庭j指标的被剥夺状态。$c_i^k$=1时, i家庭k维度的被剥夺状态保持不变; $c_i^k$=0时, i家庭k维度所有剥夺状态值都改为0。
1.2.3 多维贫困指数计算
依据Foster-Greer-Thorbecke (FGT)[31]方法, 计算贫困发生率(Hk):
$${H_k} = {q_k}/n$$ (4) $${q_k} = \sum\nolimits_{i = 1}^n {c_i^k} $$ (5) 式中:${q_k}$是指同时存在k个维度贫困的家庭数; n指总样本数, 本文中为172。
因通过FGT方法得到的贫困发生率Hk对贫困发生的深度不敏感, 故本文中使用平均剥夺份额Ak来进行修正[32], 从而得到多维贫困指数Mk(MPI)。
$${M_k} = {H_k} \times {A_k}$$ (6) $${A_k} = \frac{{\sum {g_{ij}^k{w_j}} }}{{{q_k}}}$$ (7) 式中: Hk为多维贫困发生率, 代表研究区多维贫困的广度; Ak为平均剥夺份额, 代表研究区多维贫困的深度。
1.2.4 单一指标对多维贫困的贡献率
$${\rm{CT}}_J^K = \frac{{\sum\nolimits_{i = 1}^n {g_{ij}^k} }}{{\sum\nolimits_{j = 1}^9 {\sum\nolimits_{i = 1}^n {g_{ij}^k} } }}$$ (8) 式中:${\rm{CT}}_J^K$为j指标对k维贫困的贡献率, $g_{ij}^k$表示k维度下i家庭j指标的被剥夺状态。
2. 结果与分析
2.1 北冶乡单一维度贫困状况分析
从单一维度分析北冶乡的贫困状况, 人均耕地面积、技能培训、卫生及教育4个方面的1维贫困率均超过90%, 饮用水方面存在贫困的家庭也高至81.4%。传统意义上表示贫困的年人均收入占比仅为39.53%(表 3), 在9个指标中其重要性居第7位, 说明仅以收入划分贫困线的方式已不适用。
表 3 平山县北冶乡单一维度贫困率Table 3. Single dimension poverty rate in Beiye Township, Pingshan County收入Income 资本Capital 生活水平Standard of living 年人均收入
Annual net income per capita人均耕地面积
Arable land area per capita教育
Education技能培训
Skills training卫生设施
Health facilities资产
Asset饮用水
Drinking water健康
Health燃料
Fuel贫困率Poverty rate (%) 39.53 97.09 90.12 94.77 93.60 12.79 81.40 45.93 20.35 由表 3可以看出, 北冶乡贫困主要表现为资本维度的缺失。受山区土壤条件与坡度的限制, 大部分家庭人均耕地面积小于0.03 hm2, 远小于平山县人均水平(0.106 hm2)及平山县贫困标准值(0.064 hm2); 同时, 山区地形限制了村落的外扩, 而不通达的交通条件也减弱了村落之间的联系, 以至于教育资源不能很好地整合与共享, 很多村子没有学校或只设有小学(只设一年级和二年级), 教育缺失相对严重; 调查表明, 多数山区村庄已变为“老年村”, 因为技能培训的缺失, 为维持生计, 村内年轻人外出务工者居多, 而人力资源的外流减弱了政府或社会机构对村落的关注度, 进一步加剧了技能培训这一资本的缺失。
2.2 北冶乡多维贫困状况分析
北冶乡多维贫困从贫困广度(多维贫困发生率H)与贫困深度(贫困剥夺份额A)两方面展开分析。从贫困广度看, 贫困维度(k)≤3时, 研究区90%以上家庭处于贫困状态, 即几乎所有家庭有至少3个指标同时被剥夺。按照UNDP(联合国开发计划署, United Nations Development Programme)的定义[33], 30%左右指标(k=3)被剥夺的农户为贫困户, 也就是说研究区有90%家庭属于贫困户(表 4)。从贫困深度看, 随着维度k值的增加, 贫困剥夺份额呈逐渐增加态势, 也就是说, 随着维度的增加, 虽然贫困广度降低了, 但贫困深度是增加的。
表 4 平山县北冶乡多维贫困发生率与多维贫困指数Table 4. Multi-dimensional poverty incidence and poverty index in Beiye Township, Pingshan County贫困维度(k)
Poverty dimension多维贫困发生率(H)
Multi-dimensional poverty incidence贫困剥夺份额(A)
Poverty deprivation share多维贫困指数(M)
Multi-dimensional poverty index收入贫困发生率
Income poverty rate1 1.00 0.60 0.60 0.38 2 0.98 0.60 0.59 0.38 3 0.90 0.62 0.56 0.38 4 0.73 0.67 0.49 0.38 5 0.47 0.77 0.36 0.38 6 0.45 0.80 0.36 0.38 7 0.27 0.85 0.23 0.38 8 0.06 0.93 0.06 0.38 9 0.00 0.38 多维贫困线是指贫困维度k与总维度9的比值, k=3时的多维贫困线为0.33, 对应的多维贫困指数为0.56, 说明研究区的多维贫困程度相对较大。随着k值的增加, 多维贫困指数逐渐降低, 即, 随着被剥夺维度的增加, 研究区家庭陷入贫困的概率逐渐降低。当k < 7时, 多维贫困发生率大于收入贫困发生率, 非收入贫困样本数量多于收入贫困样本数量, 说明从多维贫困的视角看, 收入贫困也已不是家庭贫困的主因, 对贫困状况进行多维测评更科学合理。
为深入分析北冶乡的多维贫困状况, 本文计算了9个指标对多维贫困的贡献率(表 5)。总体来讲, 随着k值的增加, 年人均收入与燃料2个指标对多维贫困的贡献率基本呈逐渐增加趋势, 说明北冶乡收入缺失与燃料缺失户数相对较多; 人均耕地面积、教育、技能培训与卫生设施4个指标变化不大, 其贡献率集中于13.58%~18.18%, 这4个指标缺失的普遍性较强; k > 5时, 技能培训、卫生设施与饮用水3个指标的贡献率逐渐降低, 说明相对于低维贫困状态, 高维贫困状态下, 这3个指标缺失的农户大幅减少。
表 5 平山县北冶乡贫困指标对多维贫困的贡献率Table 5. Contribution rates of poverty indexes to multi-dimensional poverty in Beiye Township, Pingshan County% 贫困维度(k)
Poverty dimension年人均收入
Annual income per capita人均耕地面积
Cultivated area per capita教育
Education技能培训
Skills training卫生设施
Health facilities资产
Assets饮用水
Drinking water健康
Health燃料
Fuel1 6.98 15.70 15.70 16.28 16.86 2.33 14.53 8.14 3.49 2 6.98 15.70 15.70 16.28 16.86 2.33 14.53 8.14 3.49 3 7.74 16.13 14.84 16.13 17.42 2.58 13.55 7.74 3.87 4 9.52 15.08 16.67 16.67 16.67 3.17 12.70 6.35 3.17 5 13.58 13.58 16.05 14.81 16.05 2.47 11.11 7.41 4.94 6 16.67 14.10 16.67 15.38 16.67 0.00 10.26 5.13 5.13 7 17.39 17.39 13.04 10.87 13.04 0.00 10.87 6.52 6.52 8 18.18 18.18 18.18 8.33 8.33 0.00 8.33 8.33 8.33 2.3 教育缺失家庭多维贫困状况分析
2.3.1 教育缺失对多维贫困的影响分析
调查过程中, 被调研人员多次提到由于学历不高, 很多技能都不会。基于此, 本研究着重分析了教育缺失家庭的多维贫困状况(表 6)。可以看出, 2维贫困下, 教育缺失的贡献已高达77.60%, 即100个家庭存在2个贫困指标, 教育缺失状况出现在77.60个家庭中。而且随着维度k的增大, 教育缺失对家庭贫困的贡献越来越大, k > 3时出现极端情况, 即样本中贫困全部发生在教育缺失的家庭, 也就是说凡是有3个以上贫困指标的家庭必定存在教育缺失。
表 6 平山县北冶乡教育缺失对多维贫困的贡献Table 6. Contribution of education loss to multi-dimensional poverty in Beiye Township, Pingshan County贫困维度(k)
Poverty dimension教育缺失Lack of education 教育未缺失Fully educated 多维贫困指数(M)
Multidimensional poverty index贡献
Contribution (%)多维贫困指数(M)
Multidimensional poverty index贡献
Contribution (%)2 0.65 77.60 0.37 22.40 3 0.65 79.95 0.32 20.05 4 0.61 100.00 0.00 0.00 5 0.51 100.00 0.00 0.00 2.3.2 基于家庭特征的教育缺失对3维贫困的影响分析
为深入分析教育缺失对农村多维贫困的影响, 本文对农户较关心的收入指标进行分解, 从家庭收入、主要收入来源及家庭人口规模3个方面展开分析(表 7)。此方面内容以3维贫困为例进行研究, 3维贫困条件下教育缺失的家庭收入明显低于教育未缺失的家庭, 月收入1 000元以下的家庭全部存在教育缺失情况, 而教育未缺失家庭中有47.95%的家庭月收入高于5 000元。从收入来源来看, 农业生产已经无法满足农村居民生活所需, 教育未缺失的家庭有更多的收入来源, 其中近一半家庭主要收入来源为外出务工。从家庭人口规模来看, 家庭人口规模越大, 越容易发生多维贫困, 但相对来讲, 未发生教育缺失的家庭受人口规模影响较小。总体而言, 教育缺失家庭的收入来源更单一、家庭人口规模更大, 经济收入也相对未缺失家庭更低。
表 7 基于家庭特征的教育缺失对3维贫困的贡献Table 7. Contribution of education loss to 3-dimensional poverty based on family feature项目Item 教育缺失
Lack of education (%)教育未缺失
Fully educated (%)家庭月收入
Family’s month income (¥)< 1 000 38.14 0.00 1 000~3 000 12.37 26.03 3 000~5 000 34.02 26.03 > 5 000 15.46 47.95 主要收入来源
Main income sources农产品Agricultural products 12.37 26.03 农副产品
Agricultural byproducts15.46 0.00 外出务工Migrant work 42.27 47.95 其他Others 29.90 26.03 人口Population 1~2 10.31 26.03 3~4 16.49 21.92 ≥5 73.20 52.05 3. 讨论与结论
3.1 讨论
3.1.1 贫困山区致贫机理探讨
贫困是复杂而综合的, 山区村落受自然条件与区位条件双重限制, 致贫因素更是复杂。经上文分析, 河北省平山县北冶乡居民的主要困难有耕地面积少、教育水平低、无一技之长及卫生条件差, 因此, 本文立足于这4个指标, 进一步对太行山区贫困农村的致贫机理进行探讨。
众所周知, 山区交通条件差, 这就导致山区村落相对平原地区易闭塞, 同时地形又限制了村落的外扩, 造就了山区村庄小且呈散点式分布的特点, 先进的教育资源难以流入且难以整合[2, 34], 故山区整体呈现教育水平低的特点。较低的教育水平直接导致了山区人民技能的缺失, 被调查村民大都以种植农作物为生, 经济来源比较单一, 而平山县具有太行山脉的典型特点——土层薄、岩石风化层持水能力差, 植被长势差[35]且水土流失严重[36], 土壤条件很多时候并不能满足农作物的生长条件, 山区村民基本都是靠天吃饭, 因此, 太行山区人民收入水平远低于我国平均水平。低水平教育的另一个弊端就是村民思想觉悟相对较低, 对存在的卫生隐患警惕性不高, 间接影响了村民的身体健康状况。
综上, 太行山区的区位与自然条件是其贫困的根本因素, 但这是由地理条件决定的, 按照“顺应自然”的原则, 是不应改变的。因此, 从社会层面讲, 本文认为教育水平低是山区贫困的主因。
3.1.2 山区脱贫路径探讨
本文研究表明教育与耕地等是山区农村存在的主要问题, 因此, 整合土地资源与教育资源、提高土地利用率在山区农村脱贫方面显得尤为重要, 而资源整合的重要前提是农村居民点整理。山区居民点分布多受坡度等地形因素影响, 居民点优化是解决居民点布局分散与土地利用效率低的重要途径, 目前采取的优化策略主要包括等级优化、撤并优化、农户主导优化、功能主导优化等模式[37]。经实地调查发现, 北冶乡随着地形坡度的增大, 生产条件和居住环境相对变差, 居民点分布零散, 规模小。而且, 坡度较大的地区也比较容易发生各种地质灾害, 同时还存在基础设施建设困难、农业规模化生产较难的困境。综上, 建议在农村居民点整理潜力测算的基础上, 采用等级优化的模式, 将坡度较大且土地集约利用程度较差的居民点作为综合整治的重点对象[1, 33, 38]。
另一方面, 可结合山区地理特征扶持特色产业, 探究政府、社会、村民联合机制, 形成产业链, 产品直销, 形成支柱产业, 带动贫困人口[39]。依托旅游资源, 高海拔陡峭地建立经济林、生态林, 低海拔平缓地开展山区特色农业种植, 结合农村居民点整理结果, 优化现有国土空间布局, 以此助力山区脱贫[40-41]。
3.2 结论
本文以位于太行山区的河北省平山县北冶乡实地调查问卷结果为基础数据, 分析了基于A-F多维测度模型的北冶乡多维贫困状况, 并在此基础上对致贫机理与脱贫路径进行了探讨, 主要结果如下:
1) 北冶乡单维贫困状况仍较严重, 各维度贫困发生率存在显著差异。贫困主要表现为资本维度的缺失, 资本维度下几个指标的贫困发生率均超过90%, 其次为生活水平维度, 收入对贫困的贡献率并不高。
2) 北冶乡多维贫困程度较深。从多维贫困广度看, 超过90%的家庭为贫困户(3维贫困), 而多维贫困深度随维度k的增加呈增加的态势。多维贫困指数则随维度k的增加而降低, 说明被剥夺维度越大, 陷入贫困的概率越低。
3) 各指标对北冶乡多维贫困的贡献存在显著差异。人均耕地面积、教育、技能培训与卫生设施4个指标缺失的普遍性较强, 是太行山区精准扶贫应着重关注的方面; 技能培训、卫生设施与饮用水3个指标缺失情况随维度k的增加而有所好转, 但变化幅度并不大; 高维贫困中, 收入指标贡献逐渐增加, 也需要重点关注。
4) 教育缺失是导致贫困程度加大的主要原因与内在因素, 相对于教育未缺失家庭, 教育缺失家庭的月收入更低、收入来源更单一、家庭人口规模更大。因此, 建议采用等级优化的模式整理农村居民点, 从而进行教育资源整合与优化, 以此助力山区脱贫。
-
![]()
图 2 研究区辅助变量土壤类型(a)、土地利用类型(b)、海拔(c)和坡度(d)的映射
Figure 2. Mapping of auxiliary variables in the study area. a: soil type; b: land use type; c: altitude; d: slope.
![]()
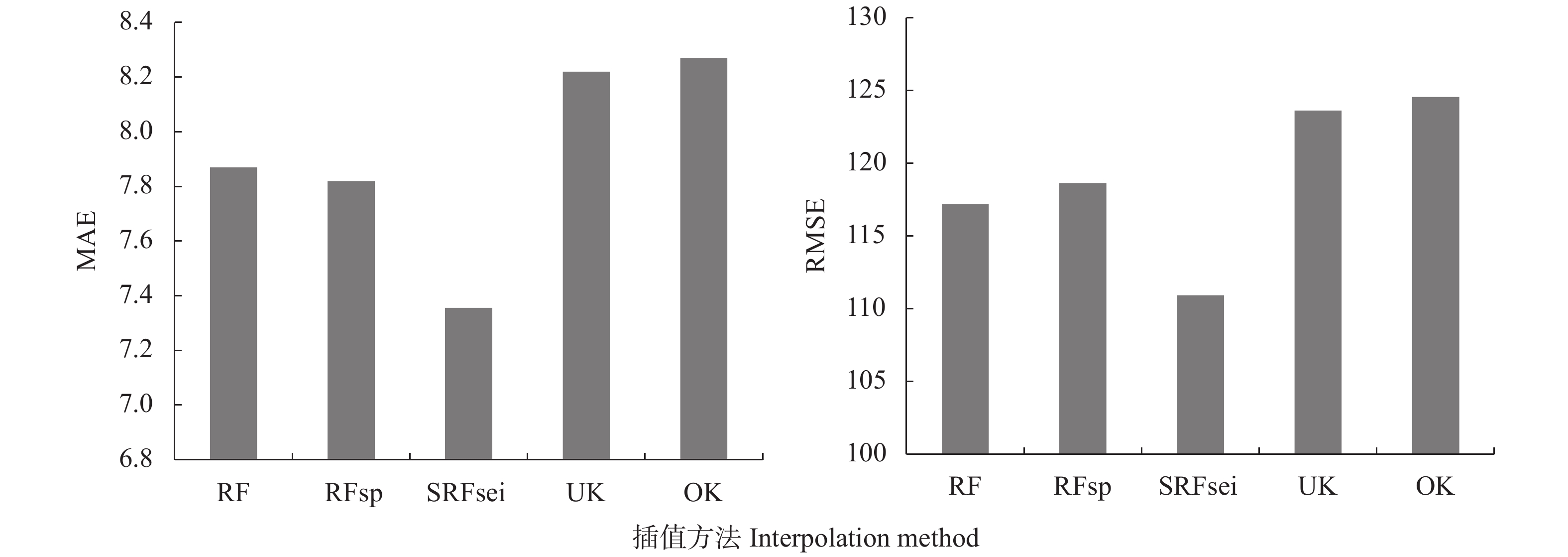
图 4 不同插值方法交叉验证结果的平均绝对误差(MAE)和均方根误差(RMSE)
RF: 随机森林法; RFsp: 随机森林空间预测框架; SRFsei: 融合半变异函数的空间随机森林插值法; UK: 泛克里金; OK: 普通克里金。
Figure 4. Mean absolute error (MAE) and root mean square error (RMSE) of cross-validation results of different interpolation methods
RF: random forest; RFsp: random forest for spatial predictions framework; SRFsei: spatial random forest with semi-variogram interpolation; UK: universal Kriging; OK: ordinary Kriging.
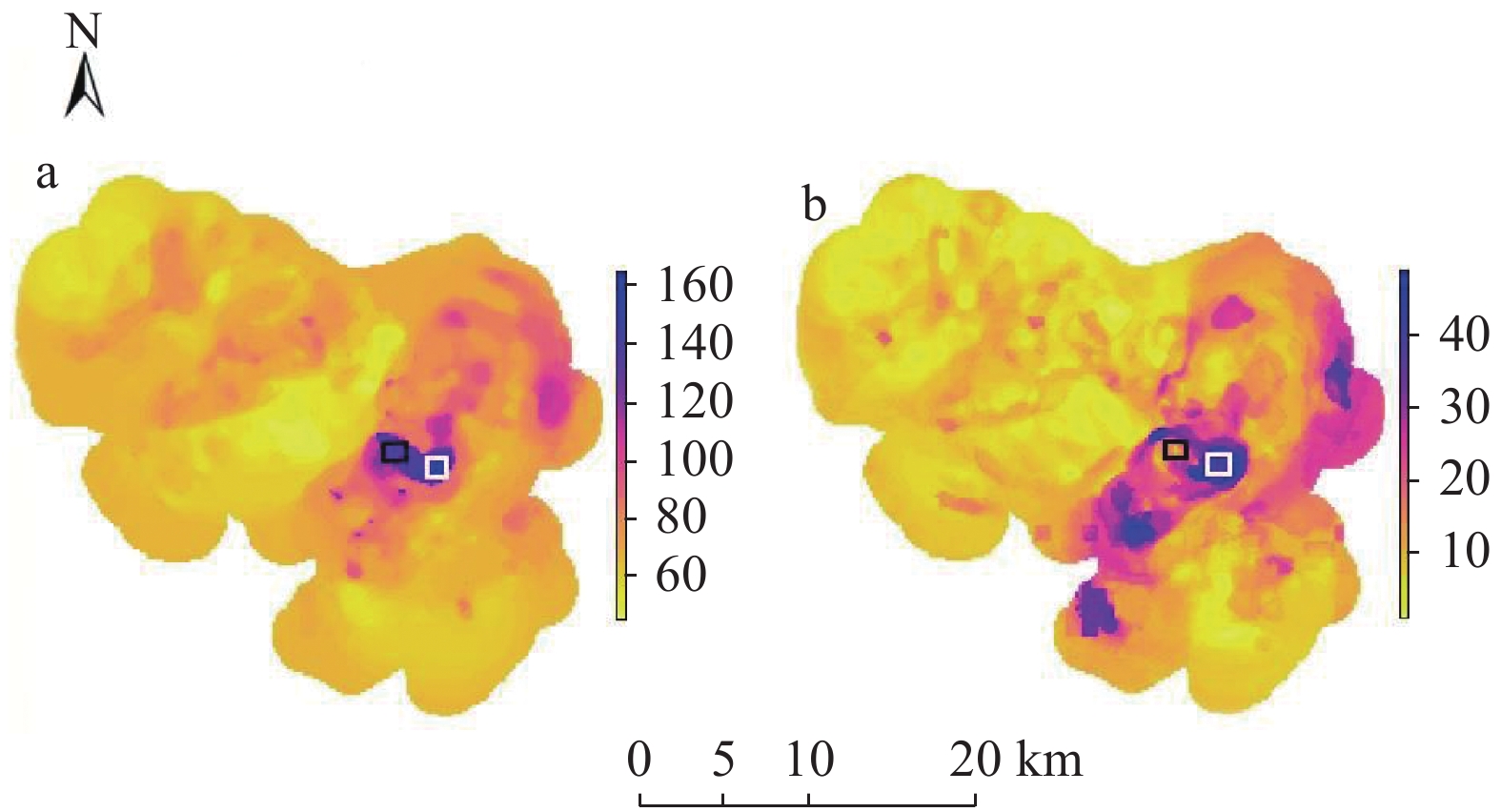
![]()
图 5 融合半变异函数的空间随机森林插值法的插值结果图(a)与误差标准差图(b)
Figure 5. Interpolation results (a) and standard deviation variance of error (b) of spatial random forest with semi-variogram interpolation
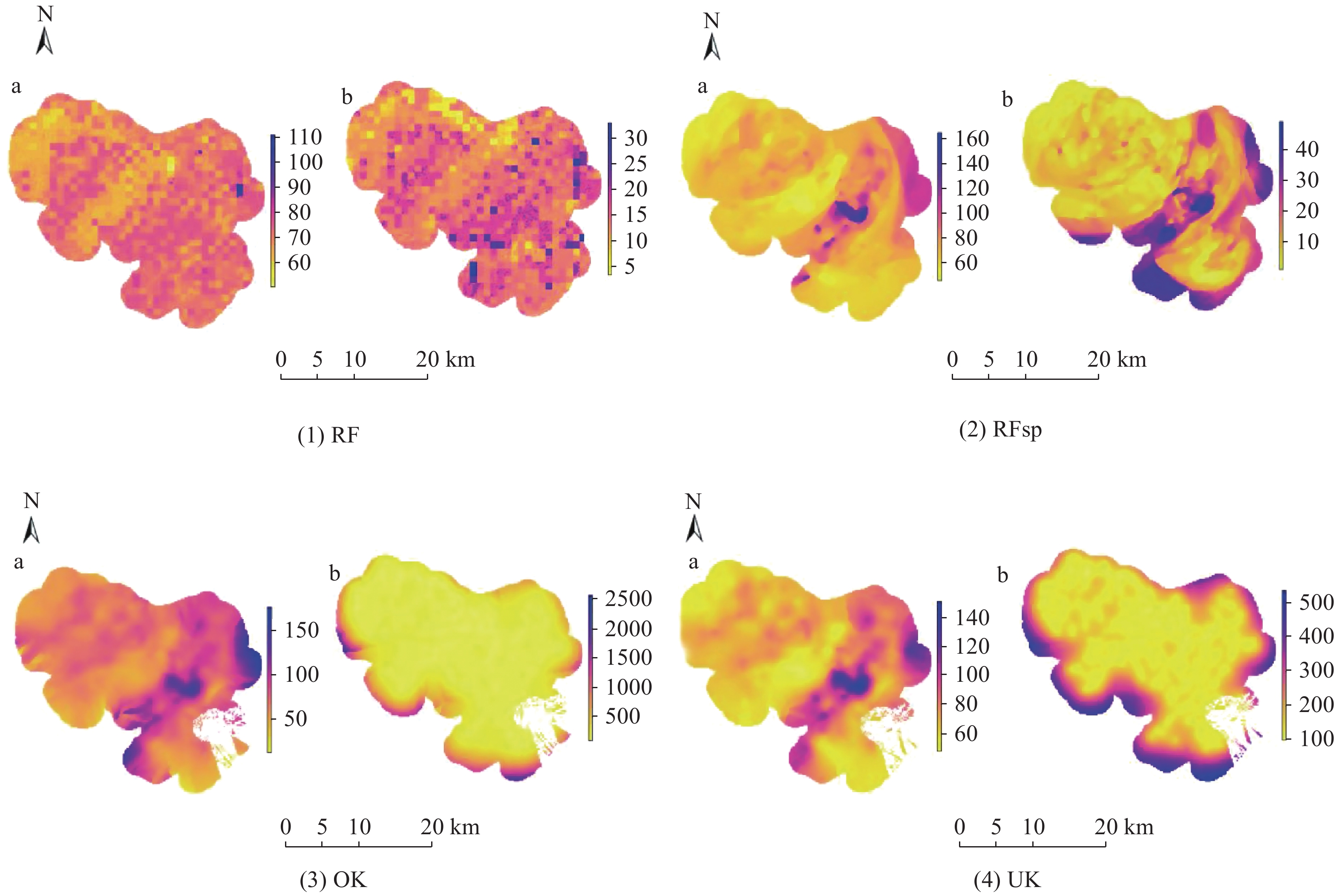
![]()
图 6 不同插值方法的插值结果图(a)及误差标准差图(b)
RF: 随机森林法; RFsp: 随机森林空间预测框架; OK: 普通克里金; UK: 泛克里金。
Figure 6. Interpolation results (a) and standard deviation variance of error (b) of different interpolation methods
RF: random forest; RFsp: random forest for spatial predictions framework; OK: ordinary Kriging; UK: universal Kriging.
-
[1] LIU P, HU W Y, TIAN K, et al. Accumulation and ecological risk of heavy metals in soils along the coastal areas of the Bohai Sea and the Yellow Sea: a comparative study of China and South Korea[J]. Environment International, 2020, 137: 105519 doi: 10.1016/j.envint.2020.105519
[2] RAI P K, LEE S S, ZHANG M, et al. Heavy metals in food crops: Health risks, fate, mechanisms, and management[J]. Environment International, 2019, 125: 365−385 doi: 10.1016/j.envint.2019.01.067
[3] WANG Q, XIE Z Y, LI F B. Using ensemble models to identify and apportion heavy metal pollution sources in agricultural soils on a local scale[J]. Environmental Pollution, 2015, 206: 227−235 doi: 10.1016/j.envpol.2015.06.040
[4] LIU J, LIU Y J, LIU Y, et al. Quantitative contributions of the major sources of heavy metals in soils to ecosystem and human health risks: a case study of Yulin, China[J]. Ecotoxicology and Environmental Safety, 2018, 164: 261−269 doi: 10.1016/j.ecoenv.2018.08.030
[5] HOU D Y, OʹCONNOR D, NATHANAIL P, et al. Integrated GIS and multivariate statistical analysis for regional scale assessment of heavy metal soil contamination: a critical review[J]. Environmental Pollution, 2017, 231: 1188−1200 doi: 10.1016/j.envpol.2017.07.021
[6] 陈昕. 基于GIS的柘塘镇土壤重金属污染的空间格局分析与预测[D]. 南京: 南京农业大学, 2016 CHEN X. The spatial pattern analysis and prediction of soil heavy metal based on GIS in Zhetang Town[D]. Nanjing: Nanjing Agricultural University, 2016
[7] MAHMOUDABADI E, SARMADIAN F, NAZARY MOGHADDAM R. Spatial distribution of soil heavy metals in different land uses of an industrial area of Tehran (Iran)[J]. International Journal of Environmental Science and Technology, 2015, 12(10): 3283−3298 doi: 10.1007/s13762-015-0808-z
[8] ZHANG L X, ZHU G Y, GE X, et al. Novel insights into heavy metal pollution of farmland based on reactive heavy metals (RHMs): Pollution characteristics, predictive models, and quantitative source apportionment[J]. Journal of Hazardous Materials, 2018, 360: 32−42 doi: 10.1016/j.jhazmat.2018.07.075
[9] GOODCHILD M F. GIScience, geography, form, and process[J]. Annals of the Association of American Geographers, 2004, 94(4): 709−714
[10] LI J, HEAP A D. A review of comparative studies of spatial interpolation methods in environmental sciences: Performance and impact factors[J]. Ecological Informatics, 2011, 6(3/4): 228−241
[11] LI J, HEAP A D. Spatial interpolation methods applied in the environmental sciences: a review[J]. Environmental Modelling & Software, 2014, 53: 173−189
[12] WANG J F, HAINING R, LIU T J, et al. Sandwich estimation for multi-unit reporting on a stratified heterogeneous surface[J]. Environment and Planning A: Economy and Space, 2013, 45(10): 2515−2534 doi: 10.1068/a44710
[13] GAO B B, HU M G, WANG J F, et al. Spatial interpolation of marine environment data using P-MSN[J]. International Journal of Geographical Information Science, 2020, 34(3): 577−603 doi: 10.1080/13658816.2019.1683183
[14] ZHU A X, LU G N, LIU J, et al. Spatial prediction based on Third Law of Geography[J]. Annals of GIS, 2018, 24(4): 225−240 doi: 10.1080/19475683.2018.1534890
[15] LIN Y P, CHENG B Y, CHU H J, et al. Assessing how heavy metal pollution and human activity are related by using logistic regression and kriging methods[J]. Geoderma, 2011, 163(3/4): 275−282
[16] BREIMAN L. Statistical modeling: The two cultures[J]. Statistical Science, 2001, 16(3): 199−231 doi: 10.1214/ss/1009213725
[17] TAN Z, YANG Q, ZHENG Y. Machine learning models of groundwater arsenic spatial distribution in Bangladesh: influence of holocene sediment depositional history[J]. Environmental Science & Technology, 2020, 54(15): 9454−9463
[18] FOTHERINGHAM A S, BRUNSDON C, CHARLTON M. Geographically weighted regression: The analysis of spatially varying relationships[J]. Geographical Analysis, 2003, 35(3): 272−275
[19] GEORGANOS S, GRIPPA T, NIANG GADIAGA A, et al. Geographical random forests: a spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling[J]. Geocarto International, 2021, 36(2): 121−136 doi: 10.1080/10106049.2019.1595177
[20] HENGL T, HEUVELINK G B M, ROSSITER D G. About regression-kriging: From equations to case studies[J]. Computers & Geosciences, 2007, 33(10): 1301−1315
[21] HENGL T, NUSSBAUM M, WRIGHT M N, et al. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables[J]. PeerJ, 2018, 6: e5518 doi: 10.7717/peerj.5518
[22] SEKULIĆ A, KILIBARDA M, HEUVELINK G B M, et al. Random forest spatial interpolation[J]. Remote Sensing, 2020, 12: 1687 doi: 10.3390/rs12101687
[23] HEUNG B, BULMER C E, SCHMIDT M G. Predictive soil parent material mapping at a regional-scale: a Random Forest approach[J]. Geoderma, 2014, 214/215: 141−154 doi: 10.1016/j.geoderma.2013.09.016
[24] 齐杏杏, 高秉博, 潘瑜春, 等. 基于地理探测器的土壤重金属污染影响因素分析[J]. 农业环境科学学报, 2019, 38(11): 2476−2486 doi: 10.11654/jaes.2019-0537 QI X X, GAO B B, PAN Y C, et al. Influence factor analysis of heavy metal pollution in large-scale soil based on the geographical detector[J]. Journal of Agro-Environment Science, 2019, 38(11): 2476−2486 doi: 10.11654/jaes.2019-0537
[25] GAO B B, LU A X, PAN Y C, et al. Additional sampling layout optimization method for environmental quality grade classifications of farmland soil[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(12): 5350−5358 doi: 10.1109/JSTARS.2017.2753467
-
期刊类型引用(2)
1. 刘梓萌,李璐,李昊天,刘娜,王鸿玺,邵立威. 华北平原40年夏玉米作物系数变化及影响因素. 中国生态农业学报(中英文). 2023(09): 1355-1367 .  本站查看
本站查看
2. 孙思琦,陈永喆,王聪,胡庆芳,吕一河. 华北地区生态保护与恢复的水资源效应研究. 中国工程科学. 2022(05): 97-106 . 百度学术
其他类型引用(4)

 下载:
下载:

计量
- 文章访问数: 867
- HTML全文浏览量: 518
- PDF下载量: 172
- 被引次数: 6
